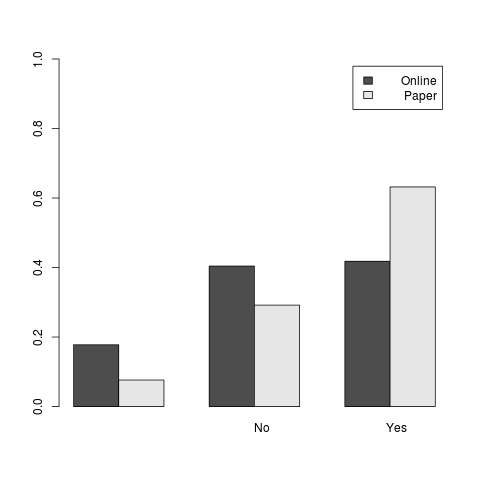'name:poa06-area-lambert'setwd("~/projects/POA_centroids/POA2006_centroids")library(swishdbtools)ch<-connect2postgres2("delphe")fout_geo=dbGetQuery(ch,'select poa_2006,
st_area(st_transform(the_geom, 3112))/1000000 as Geoscience_Australia_Lambert_area_km2,
st_x(st_centroid(st_transform(the_geom,3112))) as geocentx,
st_y(st_centroid(st_transform(the_geom,3112))) as geocenty
from abs_poa.auspoa06')str(fout_geo)sum(fout_geo$geoscience_australia_lambert_area_km2)write.table(fout_geo,'data_derived/auspoa06_geocentroids_lambert_20160624.csv',row.names=F,sep=',')plot(fout_geo[,3:4])head(fout_geo)nrow(fout_geo)2507
I have also now extracted several slides into a template outline for reviewing epidemiological and other research.
Adrian Sleigh’s Protocol
Object of Study, Hypotheses or Research Questions
Purpose of Study: Objectives of study; why was it done?
Reference Population:
To whom do authors generalize results?
To whom should the findings be generalized?
Sampling
From the Reference Pop (target population) ->
Source Pop -> Eligible population
`
The source population may be defined directly, as a matter of defining its membership criteria; or the definition may be indirect, as the catchment population of a defined way of identifying cases of the illness. The catchment population is, at any given time, the totality of those in the ‘were-would’ state of: were the illness now to occur, it would be ‘caught’ by that case identification scheme Source: Miettinen OS, 2007 http://www.teachepi.org/documents/courses/fundamentals/Pai_Lecture6_Selection%20bias.pdf
`
Sample Pop:
Refusals, Dropouts
Participants -> Study Pop
Design of study
Study setting: Where and when was the study done? What were the circumstances? Ethics?
Type of study: Experimental vs natural, descriptive vs analytical (trial, cohort, case-control, prevalence, ecological, case-report, etc). If case-control or cohort, was the timing of data collection retrospective or prospective?
Subjects: Who (number, age, sex, etc.)? How were they selected?
Comparison groups: What control group or standard of comparison? How appropriate?
Study size: Was the sample size adequate to give you confidence in the finding of “no association
Bias and Confounding
a) Selection bias: Were groups comparable for subjects who entered and stayed in study? Selection influenced by exposure (c-c) or effect (cohort) under study? Drop-outs?
b) Confounding: Control of potential confounding variables in design of the study - matching or subject restriction?
Observations
Procedure: How are the variables in the study defined and measured, ie how were data collected?
Definition of terms: Are definitions of diagnostic criteria, measurements and outcome unambiguous? Could be reproduced?
Bias and Confounding
a) Observation bias: Were study groups comparable for measurements or mode of observation? Mis-classification in determining exposure or disease categories? Differential between groups, or ‘random’?
b) Confounding: Information recorded on variables that could confound the association under study (to permit adjustment in the analysis)?
I should say though that I have found barplot can produce very customised graphs that serve a specific purpose such as that below (I have de-identified the content as this is unpublished research)
This made heavy use of the following approach
# original by Joseph Guillaume 2009
SideBySideBarPlot2<-function(aggAllData,...){par(mar=c(8,7,4,2))bp<-barplot(aggAllData,horiz=FALSE,col=gray.colors(nrow(aggAllData)),las=1,axisnames=FALSE,...)labels<-names(as.data.frame(aggAllData))text(bp,par('usr')[3],labels=labels,srt=45,adj=c(1.1,1.1),xpd=TRUE,cex=.9)return(bp)}# with width = xvar (proportions)
Until today I had no idea how to make code pretty in my blog posts which go to github after being first rendered locally so I can get the categories and tags.
But I also pushed this to another site that I do use gh-pages to build and it sent me an email complaining:
You are attempting to use the 'pygments' highlighter,
which is currently unsupported on GitHub Pages.
Your site will use 'rouge' for highlighting instead.
To suppress this warning, change the 'highlighter' value to
'rouge' in your '_config.yml'.