- In my previous post on this topic http://ivanhanigan.github.io/2015/10/how-to-effectively-implement-electronic-lab-notebooks-in-epidemiology/ I summarised some recommendations for electronic lab notebooks
- I’ve collated from a variety of sources for managing computational statistics projects in a reproducible research Pipelines
- One thing I found while reading the literature around this topic is that the concepts are difficult to really grasp until I see them being used
- The example worklog from Scott Long was a good insight into his method, that I really got more out of the figure below than from descriptions of the concept
- screen shot taken from Long, S. (2012). Principles of Workflow in Data Analysis. Retrieved from http://www.indiana.edu/~wim/docs/2012-long-slides.pdf (accessed 2015-10-23).
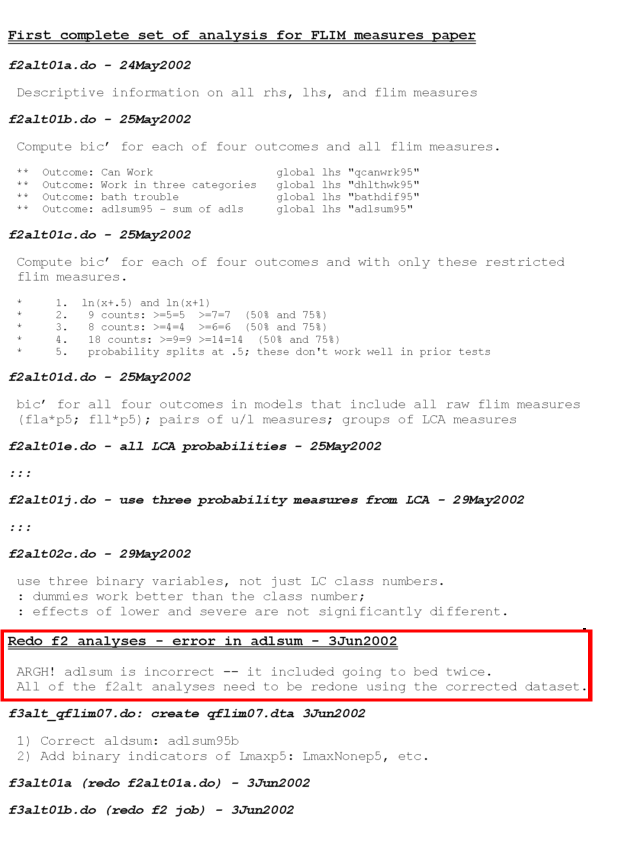
- I added a red box around an important aspect of this example, the communication of gory details, that are often difficult to track if not using a notebook to log our work
- ARGH! indeed.
Replication from Noble’s description
- That looks good, but I also really liked the description in Noble’s paper where scripts that do computations are linked to log entries
- This was something that I felt I wanted to see in action
- Without an example online, I had to have a go at creating one from the instructions
- I also had to make some modifications to the method because I want to have this set up work in a multidisciplinary team with some users on windows and others on linux, sharing the project on a network folder
My paraphrasing of Noble’s description
- Worklog: this is the main file, like a ‘lab notebook’ for the analyst to track their work. This document resides in the root of the project directory and records your progress in detail. Entries in the notebook should be dated, and they should be relatively verbose, with links or embedded images or tables displaying the results of the experiments that you performed. In addition to describing precisely what you did, the notebook should record your observations, conclusions, and ideas for future work
- For group work, this can also contain a ‘working’ folder for each person to store their messy day-to-day files that we don’t want to clutter up the main folder (eg ‘working_ivan’)
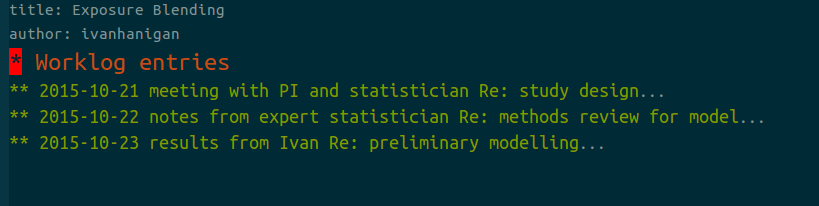
Conventions I used for writing the worklog entries are:
- Names follow this structure [**] [date in ISO 8601 YYYY-MM-DD] [meeting/notes/results] [with/from UserName] [Re: topic shortname]
- ‘meetings’ are for both agenda preparation and also notes of discussion
- ‘notes’ are such things as emailed information or ad hoc Discovery
- ‘results’ are entries related to a section of the ‘results’ folder. That is, this kind of entry is in parallel to the results entry (see below), however the log contains a prose description of the experiment, whereas the results folder contains scripts etc of all the gory details.
Tests
- I use Emacs on linux for most of my work but I need to share with windows users so tested out keeping the log in a MS word doc. This got corrupted quickly I think because I edited in Libre office.
- I decided to try and just use a plain text format
- text files created in Ubuntu are so difficult to understand (read) when opened in Windows’ Notepad. No matter how many lines have been used, all the lines appear in the same one line. To set the buffer coding to DOS style issue:
M-x set-buffer-file-coding-system utf-8-dos
a couple of examples
- As this is a plain text document opening it in emacs will not automatically render it in the Orgmode fashion
- To achieve this the command is
M-x org-modeand the file looks like below
- From here I can keep adding new entries at the bottom, and have a section for URGENT ACTION a the top
- Orgmode can expand the entries by moving to that line and hitting TAB, or use the command
C-u C-u C-u TABto expand all branches
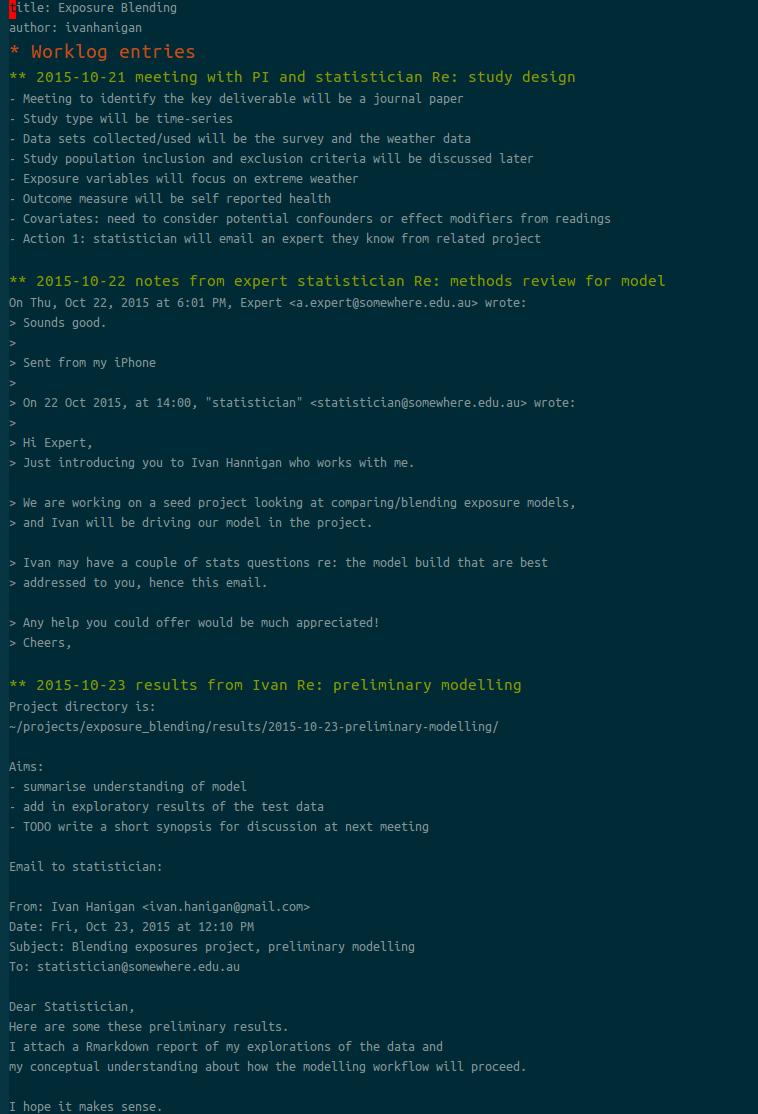
the ‘Experiment Results’ level is about work you might do on a single day, or over a week or two
- Each results subfolder would have workflow scripts that does the work
- At this level each ‘experiment’ is written up in chronological order
- It is recommended to store every command used while performing the experiment preferably as an executable script that carries out the entire experiment automatically
- you should end up with a file that is parallel to the worklog entry
- The worklog contains a prose description of the experiment, whereas the driver script contains all the gory details
- this is the level I usually think of the distribution side of things
- You may want to pack up the results from one of these folders and email it to the collaborators, or decide on the one set of tables and figures to write into the manuscript for submission to a journal
- If this is accepted for publication, this is the one combined package of ‘analytical data and code’ that I would consider putting up online as supporting information for the paper.
Example
- I followed Noble’s advice to create a driver script to set up the folder structure:
- it is in my Github R package
disentangle
> dir.create("exposures_blending")
> setwd("exposures_blending")
> disentangle::AdminTemplate()
[1] TRUE
> dir.create("results")
> setwd("results")
> makeProject::makeProject("2015-10-23-preliminary-modelling")
Creating Directories ...
Creating Code Files ...
Complete ...
>
This populates the folders as shown below
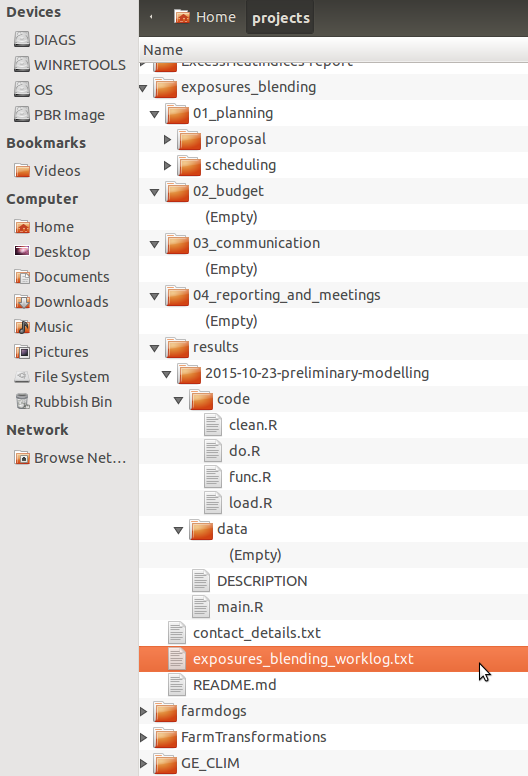
Conclusions
- I feel pretty happy with this as a replication of Noble’s method
- My colleagues can look at my work and see a high level log that links to the gory details of day to day life in the trenches
- The only downside I can see at the moment is that my colleagues on windows will see a text file that is pretty dense, and will not be as easy to navigate as a word document (or emacs org file)
- Perhaps notepad++ can be used instead. On my windows machine I did a quick experiment with NPP and found that under the Language menu > Define your language there is a method to define code folding with ** as the opening. Just need to define a closing tag. I experimented with ‘—’ which might be good, but ultimately I don’t think my colleagues are going to want to do this on their machines.