Dengue Fever (DF) and climate
DF is a mosquito borne virus that has high public health impact and is potentially strongly influenced by climate.
There is an interesting story attached to this map from a paper by Russell et al 2009 1 that draws together documentary references to historic Dengue Fever (DF) transmission, some as far south as Gosford and Bourke in NSW.
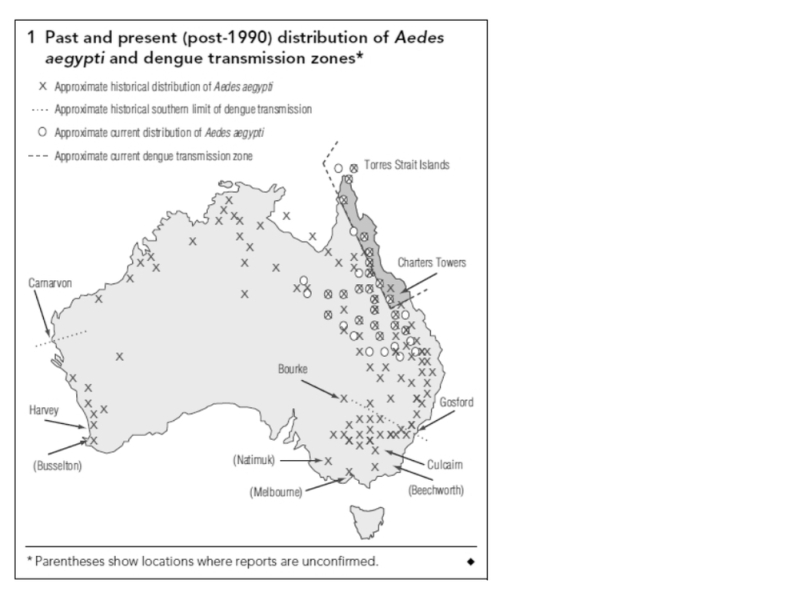
This asserted southerly extent is much further south than that delineated in the Potential Climatic Niche model of Hales et al 2002 2 and is used as a basis to refute the veracity (and utility) of such a model.
The Hales’ model determined the potential transmission zone in Australia as being constrained much further north by levels of humidity (vapour pressure). That predictive model was based on a regression of many climatic attributes of all locations of disease transmission in a global database. There is an ongoing debate between the epidemiology and the entomology camps over this modelling.
A key issue regarding this contentious map is a reference used by Russell et al 1 to dengue transmission having occurred inland at Bourke (30 S) and on the coast at Gosford (33 S, 80 km north of Sydney) in the first half of the 1900s, (ref 13 Lee et al, 1987 & ref 14 Lumley and Taylor 1943 ). However, a text search of Lee et al revealed only one reference to Gosford and that refers to the presence of vector mosquito Aedes aegypti (AE), but not dengue transmission.
The second reference is by the entomologist Frank H Taylor who mentions Brooklyn NSW, on page 158 (paragraph 2) .. as “the most southerly discovered location of AE” (the vector of DF in this area). Now, Brooklyn is on the railway on the Hawkesbury just south of Gosford. Taylor talks about railways spreading the vector. Maybe AE was found in NSW in conjunction with steam trains and railway water tanks for steam trains (the railway to Bourke was opened in 1885). There is no clear discussion in Lumley and Taylor of DF transmission around Brooklyn.
It is possible that the references cited for this map are really just evidence of the vector distribution, not actual virus transmission. It is also likely that the southern-most border of the AE vector would not be the southern-most fringe of DF transmission. This therefore casts doubt on Russell’s map which suggests the southern limit of DF transmission to have been as far south as Gosford and Bourke in NSW (Bourke is also asserted by Russell et al as a known transmission site using these same references).
What Russell may be doing is just connecting the two points - Brooklyn and Bourke (who knows if there is a single data point in between) and asserting that that line of southernmost AE proof is the southerly boundary of DF transmission. Perhaps if AE got to Brooklyn it might also have got to Bourke .. and Bourke being hotter than Brooklyn, DF transmission may have occurred there .. but we need more evidence than Russell et al provide.
(Thanks to my epidemiological friends for scouring the historical references with a thoroughly incredulous eye).