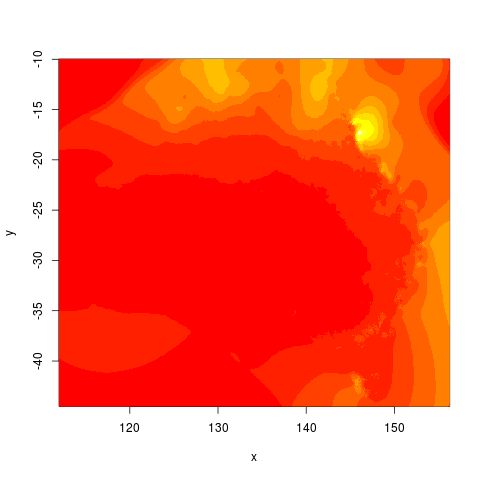
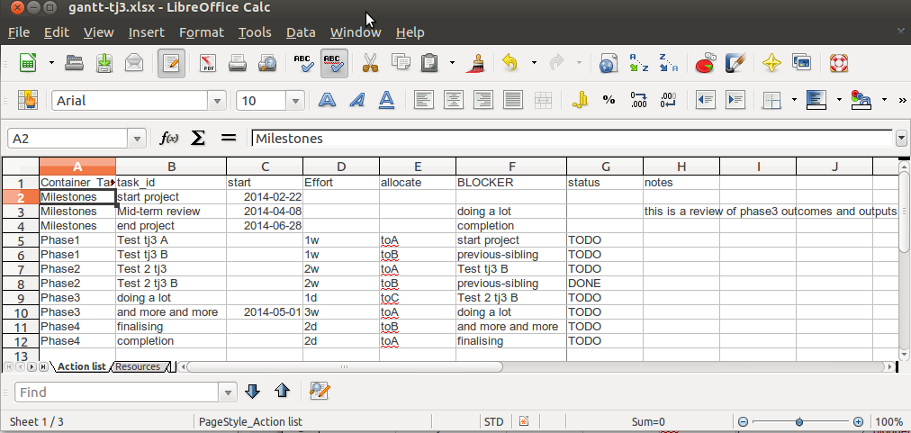
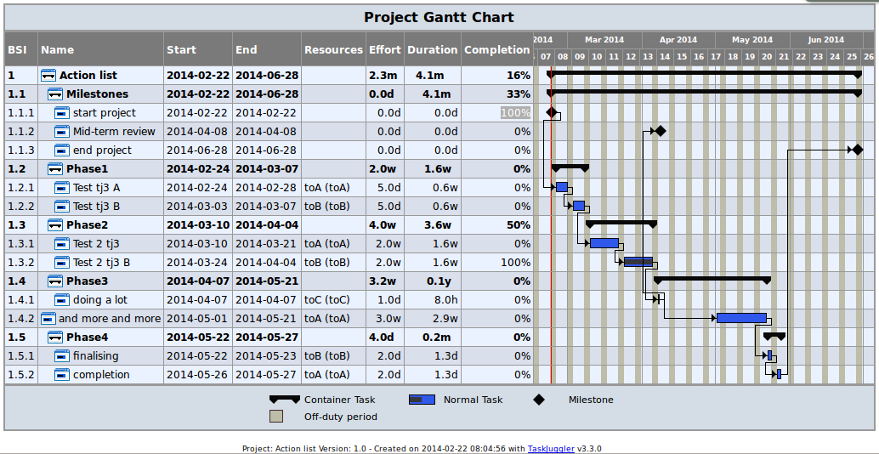
I just revised the content of the “About My Notebook” page and thought it was also relevant to post as an entry.
Welcome to my Open Notebook
This is the public face of my Open Notebook, in which I keep all the details of the data, code and documents related to my research. This is an Open Notebook with Selected Content - Delayed and aligns with the principles of the Open Notebook Science (ONS) movement. The private side of my Open Notebook (the closed bit) is private either because it includes unpublished work that I wish to keep embargoed until after publication, or because it is all the gory, messy details of the day-to-day business of writing and rewriting code and prose to analyse data and make sense of the data I am analysing. These elements of the notebook do not look like standalone journal entries and I store my personal archive either hosted by GitHub for the public parts (thanks to their superior integration with Jekyll websites thanks to gh-pages for each repository) or BitBucket for the private bits (thanks to bitbucket’s free unlimited private repositories).
Categories
The different categories can be thought of as seperate lab notebooks. My projects are connected by being placed into one of these categories.
- cloud building: the experiments I am conducting in building Virtual Labs in the cloud
- Data Documentation: how metadata tools interact with data analysis tools
- disentangle things: conceptual and methodological insights regarding complexity
- e-collaboration: my interactions with other scientists online
- ecosocial tipping points: a major branch of my research
- extreme weather events: another major branch of my research
- overview: high level information about why I am doing this stuff
- research methods: low level information about how I am doing this stuff
- spatial: technical details about how to use spatial tools
- spatial dependence: theoretical details about spatial statistics
What is Open Notebook Science? And Why am I doing it?
In 2005 Jean-Claude Bradley launched a web-based initiative called UsefulChem and named his new technique Open Notebook Science (ONS). He described it as a way of doing science in which you make all your research freely available to the public in real time. The proposed benefits include greater impact on the public good and enhanced ability to connect with like-minded collaborators. Proposed risks of ONS practice include being scooped by competitors or falling foul of Journal rules regarding prior publication and licencing of Intellectual Property. To mitigate the proposed risks the concept of ONS was broadened to allow research to be made public after a delay.
In 2010 Carl Boettiger initiated an experiment “to see if any of the purported benefits or supposed risks were well-founded.” After three years of his experiment Boettiger reported that his “evidence suggests that the practice of open notebook science can faciliate both the performance and dissemination of research while remaining compatible and even synergistic with academic publishing.”
This promising result has inspired me to follow these practices in my own part-time PhD and my full-time work as Data Manager at a University (to the extent I am allowed to by the rules of the University and the willingness of my boss to share our results).