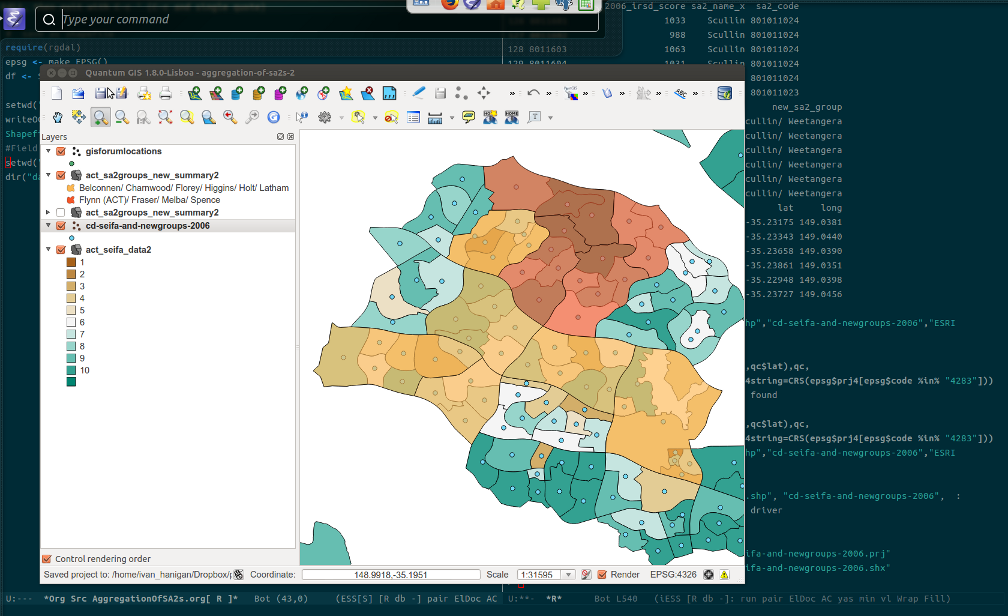
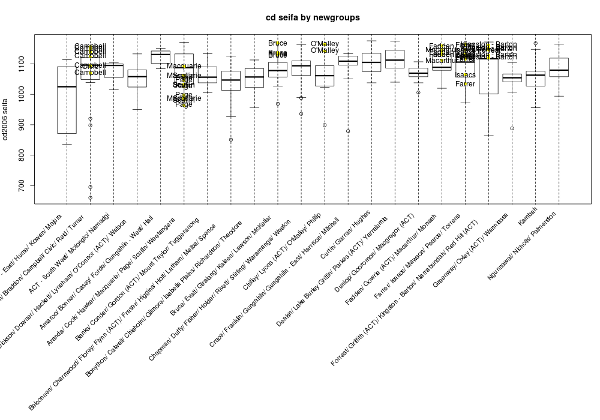
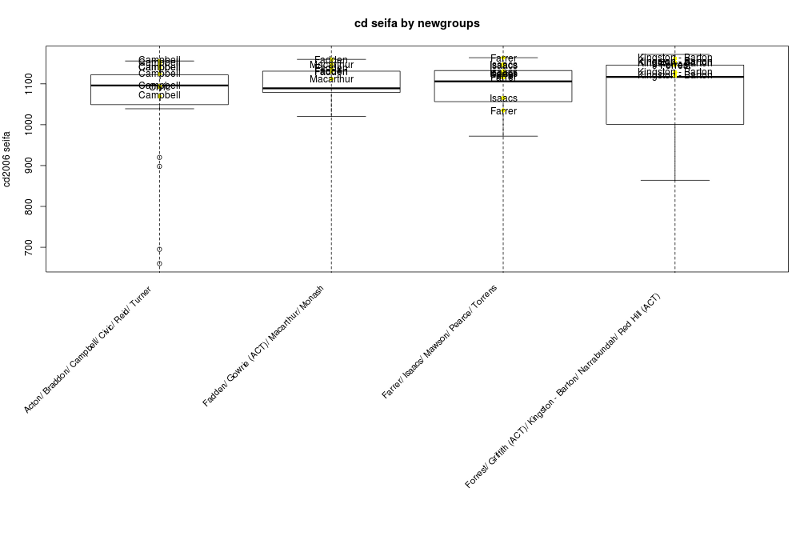
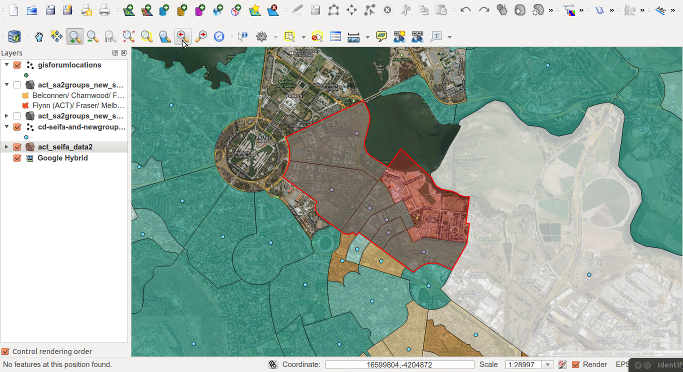
- I have been using John Myles Whites ProjectTemplate R package for ages
- I really like the ease with which I can get up and running a new project
- and the ease with which I can pick up an old project and start adding new work
Quote from John’s first post
My inspiration for this approach comes from the rails command from
Ruby on Rails, which initializes a new Rails project with the proper
skeletal structure automatically. Also taken from Rails is
ProjectTemplate’s approach of preferring convention over
configuration: the automatic data and library loading as well as the
automatic testing work out of the box because assumptions are made
about the directory structure and naming conventions that will be used
http://www.johnmyleswhite.com/notebook/2010/08/26/projecttemplate/
- I dont know anything about RoR but this philosophy works really well for my R programming too
R Code
if(!require(ProjectTemplate)) install.packages(ProjectTemplate); require(ProjectTemplate)
setwd("~/projects")
create.project("my-project")
setwd('my-project')
dir()
## [1] "cache" "config" "data" "diagnostics" "doc"
## [6] "graphs" "lib" "logs" "munge" "profiling"
## [11] "README" "reports" "src" "tests" "TODO"
##### these are very sensible default directories to create a modular
##### analysis workflow. See the project homepage for descriptions
# now all you need to do whenever you start a new day
load.project()
# and your workspace will be recreated and any new data automagically analysed in
# the manner you want
Project Administration
- I;ve found that these directories do not work so well for the administration of my projects and so I put together a different set of automatic defaults
- Ive based it on the University of Manitoba Centre for Health Policy- along with some other sources I can recall
The full set
# A.Background
# B.Proposals # C.Approvals # D.Budget
# E.Datasets
# F.Analysis
# G.Literature
# H.Communication
# I.Correspondance
# J.Meetings
# K.Completion
# ContactDetails.txt
# README.md # TODO.txt
R Code: my subset
AdminTemplate <- function(rootdir = getwd()){
setwd(rootdir)
dir.create(file.path(rootdir,'01_planning'))
dir.create(file.path(rootdir,'01_planning','proposal'))
dir.create(file.path(rootdir,'01_planning','scheduling'))
dir.create(file.path(rootdir,'02_budget'))
dir.create(file.path(rootdir,'03_communication'))
dir.create(file.path(rootdir,'04_reporting_and_meetings'))
file.create(file.path(rootdir,'contact_details.txt'))
file.create(file.path(rootdir,'README.md'))
}
Conclusion
- hopefully by formalising some of these into my workflow I will find my projects easier to navigate through
- and pick up or put down as needed