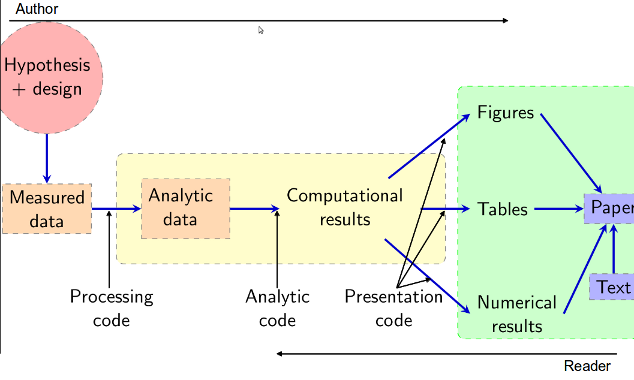
Version control
2013-12-02: This post was originally released
2015-10-02: The URL to the University Manitoba guidelines changed and has been updated.
- When we started a three year project on bushfire smoke we did some planning
- We had a deep discussion about this research management protocol from University Manitoba Centre for Health Policy http://umanitoba.ca/faculties/health_sciences/medicine/units/community_health_sciences/departmental_units/mchp/protocol/media/manage_guidelines.pdf
- That URL has changed several times since I first downloaded the guidelines, so I will also host a copy here UManitoba_MCHP_manage_guidelines.pdf
Data Management Plan Checklist
Table of Contents
1 U-Manitoba Centre for Health Policy Guidelines
These guidelines come from:
\noindent http://umanitoba.ca/faculties/medicine/units/mchp/protocol/media/manage_guidelines.pdf
Most of the material below is taken verbatim from the original. Unfortunately many of the items described below have links to internal MCHP documents that we cannot access. Nonetheless the structure of the guidelines provides a useful skeleton to frame our thinking.
The following areas should be reviewed with project team members near the beginning of the study and throughout the project as needed:
- Confidentiality
- Project team
- File organization and documentation development
- Communication
- Administrative
- Report Preparation
- Project Completion
1.1 Confidentiality
Maintaining data access
1.2 Project Team Makeup
Roles and contact information should be documented on the project website for the following, where applicable (information may also be included on level of access approved for each team member).
1.2.1 Principal Investigator
This is the lead person on the project, who assumes responsibility for delivering the project. The PI makes decisions on project direction and analysis requirements, with input from programmers and the research coordinator (an iterative process). If there is more than one PI (e.g., multi-site studies), overall responsibility for the study needs to be determined, and how the required work will be allocated and coordinated among the co-investigators. Researcher Workgroup website (internal link)
1.2.2 Research Coordinator
Th RC is always assigned to deliverables and is usually brought in on other types of projects involving multiple sites, investigators and/or programmers. Responsibilities include project documentation, project management (e.g., ensuring that timelines are met, ensuring that project specifications are being followed), and working with both investigator(s) and the Programmer Coordinator throughout the project to coordinate project requirements.
1.2.3 The Programmer Coordinator
The PC is a central management role who facilitates assignment of programming resources to projects, ensuring the best possible match among programmers and investigators. Research Coordinator Workgroup website(internal link)
1.2.4 Programmer Analyst
This is primarily responsible for programming and related programming documentation (such that the purpose of the program and how results were derived can be understood by others). However, a major role may be taken in the analyses of the project as well, and this will characteristically vary with the project. Programmer Analyst Workgroup website(internal link)
1.2.5 Research Support
This is primarily responsible for preparing the final product (i.e., the report), including editing and formatting of final graphs and manuscript and using Reference Manager to set up the references. Research support also normally sets up and attends working group meetings. All requests for research support go through the Office Manager.
1.3 Project Team considerations
1.3.1 Roles
It is important to clarify everyone's roles at the beginning of the project; for example, whether the investigator routinely expects basic graphs and/or programming logs from the programmer.
1.3.2 Continuity
It is highly desirable to keep the same personnel, from the start of the project, where possible. It can take some time to develop a cohesive working relationship, particularly if work styles are not initially compatible. Furthermore, requesting others to temporarily fill in for team absences is generally best avoided, particularly for programming tasks (unless there is an extended period of absence). The original programmer will know best the potential impact of any changes that may need to be made to programming code.
1.3.3 Access levels
Access to MCHP internal resources (e.g., Windows, Unix) need to be assessed for all team members and set up as appropriate to their roles on the project.
1.3.4 Working group
A WG is always set up for deliverables (and frequently for other projects): Terms of Reference for working group (internal)
1.3.5 Atmospherics
1.4 File organization and Documentation Development.
All project-related documentation, including key e-mails used to update project methodology, should be saved within the project directory. Resources for directory setup and file development include:
1.4.1 Managing MCHP resources
This includes various process documents as well as an overview of the documentation process for incorporating research carried out by MCHP into online resources: Documentation Management Guide (internal)
1.4.2 MCHP directory structure
A detailed outline of how the Windows environment is structured at MCHP
1.4.3 Managing project files
How files and sub-directories should be organized and named as per the MCHP Guide to Managing Project Files (internal pdf). Information that may be suitable for incorporating into MCHP online resources should be identified; for example, a Concept Development section for subsequent integration of a new concept(s) into the MCHP Concept Dictionary. The deliverable glossary is another resource typically integrated into the MCHP Glossary.
1.4.4 Recommended Directories
NOTE this is a diversion from the MCHP guidelines. These recommended directories are from a combination of sources that we have synthesised.
- Background: concise summaries: possibly many documents for main project and any main analyses based on the 1:3:25 paradigm: one page of main messages; a three-page executive summary; 25 pages of detailed findings.
- Proposals: for documents related to grant applications.
- Approvals: for ethics applications.
- Budget: spreadsheets and so-forth.
- Data
- dataset1
- dataset2
- dataset1
- Paper1
- Data
- merged dataset1 and 2
- merged dataset1 and 2
- Analysis (also see http://projecttemplate.net for a programmer oriented template)
- exploratory analyses
- data cleaning
- main analysis
- sensitivity analysis
- data checking
- model checking
- internal review
- exploratory analyses
- Document
- Draft
- Journal1
- rejected? :-(
- rejected? :-(
- Journal2
- Response to reviews
- Response to reviews
- Draft
- Versions: folders named by date - dump entire copies of the project at certain milestones/change points
- Archiving final data with final published paper
- Data
- Papers 2, 3, etc: same structure as paper 1 hopefully the project spawns several papers
- Communication: details of communication with stakeholders and decision makers
- Meetings: for organisation and records of meetings
- Contact details. table contacts lists
- Completion: checklists to make sure project completion is systematic. Factor in a critical reflection of lessons learnt.
- References
1.5 Communication
Project communication should be in written form, wherever possible, to serve as reference for project documentation. Access and confidentiality clearance levels for all involved in the project will determine whether separate communication plans need to be considered for confidential information.
1.5.1 E-mail
provides opportunities for feedback/ discussion from everyone and for documenting key project decisions. Responses on any given issue would normally be copied to every project member, with the expectation of receiving feedback within a reasonable period of time - e.g.,a few days). The Research Coordinator should be copied on ALL project correspondence in order to keep the information up to date on the project website.
- E-mail etiquette (internal)
1.5.2 Meetings
Regularly-scheduled meetings or conference calls should include all project members where possible. Research Coordinators typically arrange project team meetings and take meeting minutes, while Research Support typically arranges the Working Group meetings.
- Tips for taking notes (internal)
- Outlook calendar
Used for booking rooms, it displays information on room availability and may include schedules of team members.
1.6 Administrative
1.6.1 Time entry
Time spent on projects should be entered by all MCHP employees who are members of the project team.
- website for time entry (internal)
- procedures for time entry (internal)
1.7 Report preparation
This includes:
- Policies - e.g., Dissemination of Research Findings
- Standards - e.g., deliverable production, use of logos, web publishing
- Guidelines - e.g., producing PDFs, powerpoint, and Reference Manager files
- Other resources - e.g., e-mail etiquette, technical resources, photos.
1.7.1 Reliability and Validity Checks
Making sure the numbers "make sense". Carrying out these checks requires spelling out who will do which checks.
- Data Validity Checks
A variety of things to check for at various stages of the study. Programming can be reviewed, for example, by checking to ensure all programs have used the right exclusions, the correct definitions, etc. , and output has been accurately transferred to graphs, tables, and maps for the report.
- Discrepancies between data sources
In this case it is MCHP and Manitoba Health Reports - an example of cross-checking against another source of data.
1.8 Project Completion
Several steps need to take place to "finish" the project:
1.8.1 Final Project Meeting.
Wind-up or debriefing meetings are held shortly after public release of a deliverable. Such meetings provide all team members with an opportunity to communicate what worked/did not work in bringing the project to completion, providing lessons learned for future deliverables.
1.8.2 Final Documentation Review.
Findings from the wind-up meeting should be used to update and finalize the project website (including entering the date of release of report/paper). Both Windows and Unix project directories should be reviewed to ensure that only those SAS programs relevant to project analyses are kept (and well-documented) for future reference. Any related files which may be stored in a user directory should be moved to the project directory.
1.8.3 System Cleanup.
When the project is complete, the Systems Administrator should be informed. Project directories, including program files and output data sets, will be archived to tape or CD. Tape backups are retained for a 5-year period before being destroyed so any project may be restored up to five years after completion.
1.8.4 Integration of new material to institution repository
This is with MCHP resource repository - a general overview of this process is described in General Documentation Process {internal}.
</body>