
Adequately documenting the methods and results of data analysis helps safeguard against errors of execution and interpretation. My PhD thesis proposes that reproducible research pipelines address the problem of adequate documentation of data analysis.
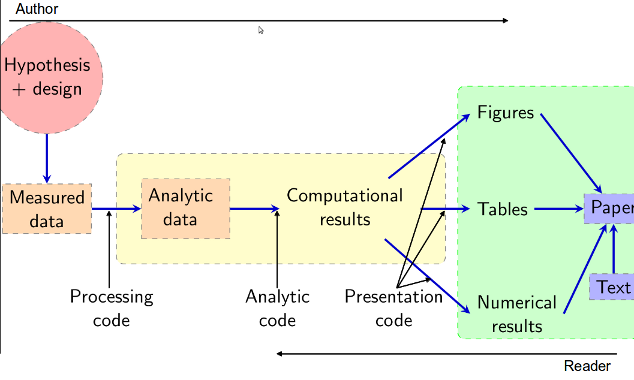
A graphical view of the reproducible research pipeline concept is shown below. The ideas were introduced into epidemiology by Peng et al in 2006, although Peng has more recently been using the terms ‘evidence based data analysis pipeline’ (Peng 2013) and ‘Data Science Pipeline’ (Peng 2015). Both terms are useful, but I chose to follow the original phrase. The graphical version shown below was introduced by Solymos and Feher (2008).
The best thing about reproducible work is not merely the ability to repeatedly arrive at the same result, but that having the organisational structures in place that are required for reproducibility also implicitly will improve the transparency and rigour of the work. This is because they make it easy to check the methods. Assumptions are easy to challenge and results verified in new analyses.
Reproducible research pipelines extend traditional research. They do this by encoding the steps in a computer ‘scripting’ language and distributing the data and code with publications. Traditional research moves through the steps of hypothesis and design, measured data, analytic data, computational results (for figures, tables and numerical results), and reports (text and formatted manuscript).
This model of the research pipeline sees a new relationship possible between the author and the reader. They approach the results and understandings of the research from opposite directions. Readers can dig deeper into the research to verify results or conduct similar studies. Reproducibility exists along a spectrum from minimum reproducibility that can be achieved by providing measured or analytic data and the analytic code. More reproducibility is gained by providing processing code necessary to transform original measured data into tidy data for analysis. Full reproducibility would include all stages of the pipeline.
References
-
Peng, R.D., Dominici, F. & Zeger, S.L. (2006). Reproducible epidemiologic research. American Journal of Epidemiology, 163, 783–789. Retrieved from http://dx.doi.org/10.1093/aje/kwj093
-
Peng, R.D. (2013). Implementing Evidence-based Data Analysis: Treading a New Path for Reproducible Research. Simply statistics. Retrieved from http://simplystatistics.org/2013/09/05/implementing-evidence-based-data-analysis-treading-a-new-path-for-reproducible-research-part-3/
-
Peng, R.D. (2015). Report Writing for Data Science in R. leanpub. Retrieved from https://leanpub.com/reportwriting
-
Sólymos, P. & Fehér, Z. (2008). The mefa package: a tool for reproducible data processing in biogeography. International Biogeography Society Newsletter. Retrieved from http://biogeography.blogspot.com.au/2008/04/mefa-package-tool-for-reproducible-data.html





